KI-Wochenpost 2024-29/31

Hallo, ja, der Abstand zum letzten Post ist etwas länger, aber ich kann mich nicht mal mit Urlaub rausreden...
Die erste Gerichtsverhandlung gegen den KI-Trainingsdatenbankpfleger LAION habe ich ja im letzten Post schon kurz angerissen. Unser AG-Mitglied Julia Laatsch hat inzwischen für ihren Heimatverband Freelens diese deutlich ausführlichere Erläuterung verfasst:
https://freelens.com/politik-medien/bericht-zum-gerichtsverfahren-laion-e-v-kneschke/
Auch sie kommt zu dem Schluss, dass es doch recht weltfremd ist, von allen, die Fotos auf ihren Websites posten, zu erwarten, dass sie sich neben ihren Foto-Jobs auch ständig auf dem Laufenden halten, unter welchen mehr oder weniger kryptischen Tarnnamen aktuell welche Bots unterwegs sind, um denen dann gezielt den Zugang zur Website zu sperren, während die für die eigenen Sichtbarkeit in Suchmaschinen wichtigen Crawler weiter reindürfen.
Alexandra Lechner weist auf diese rechtlichen Einschätzungen der Rechtsanwältin Dr. Kerstin Bäcker hin zur nach wie vor schwammigen Forderung der Gesetzgebenden nach "Maschinenlesbarkeit" von KI-Vorbehalten.
Am Ende landet allerdings auch dieser Artikel zur praktischen Umsetzung wieder beim Beispiel des hochkomplexen robots.txt-Files der New York Times, das ich auch im letzten Post zitiert habe - eigentlich als abschreckendes Beispiel dafür, welch nerdische Frickelei es ist, eine solche Hausverbots-Liste zusammenzustellen.
Dabei kommt mir gerade folgende Idee: So wie es heute für Webshop-Betreiber notgedrungen üblich ist, aus Angst vor formalen (von bösen Anwaltsbots erstellten) Abmahnungen Abos bei darauf spezialisierten (wohlmeinenden) Anwälten abzuschließen, die einen mit fortwährend aktualisierten AGBs versorgen, könnte doch mal jemand darauf verfallen, tagesfrische robots.txt-Dateien zu erzeugen, die Abonnierende automatisch in ihre Website einbinden. Komfortablerweise könnte man als KundIn eines solchen Services aus einem reichhaltigen Menü ankreuzen, welche Sorte Crawler man zulassen will und welche nicht. Da die derzeitigen robot-Tags genau solche eine inhaltliche Spezifikation nicht erlauben, obläge es dann dem Hausverbots-Provider, daraus eine Liste mit stubenreinen und unerwünschten Bots zu generieren.
Sind Programmierende unter den Lesenden, die Lust haben, daraus ein Geschäft zu machen? Oder fühlt sich vielleicht einer unserer Mitgliedsverbände berufen und in der Lage, das als Service für seine Mitglieder anzubieten?
Nun aber zur Erklärung des merkwürdigen Titelbilds:
Verschiedene Experten weisen in letzter Zeit immer häufiger darauf hin, dass der KI-Hype wirtschaftlich auf durchaus wackeligen Beinen steht und derzeit vor allem einem gigantische Geldverbrennung befeuert. So schätzt der üblicherweise sehr gut informierte Branchendienst "The Information", dass OpenAI (das mit ChatGPT den Boom zumindest in der öffentlichen Wahrnehmung erst so richtig gezündet hat) dieses Jahr rund 5 Milliarden Dollar Verlust anhäufen könnte.
Dafür verantwortlich sind vor allem die enormen Kosten für das Training der immer komplexeren Modelle und den Betrieb der monströsen Rechenzentren, auf denen die Services laufen. Die jüngst vorgestellte Version GPT4o wirkt auf manche Beobachter vor diesem Hintergrund fast wie eine Verzweiflungstat, da sie einerseits nicht wirklich neue Leistungsmerkmale aufweist, sondern eher die bekannten Schwächen hinter einer glänzenderen Oberfläche versteckt, wie etwa der Scarlett-Johanssonesken Stimme, die ja auch prompt nach juristischem Geplänkel wieder in der Versenkung verschwand. Andererseits steigt OpenAI mit der kostenlosen Version in einen mutmaßlich ruinösen Preiskampf mit Konkurrenten ein, der viele Merkmale eines klassischen "Race to the Bottom" aufweist, in einem Markt der nach wie vor Schwierigkeiten hat, langfristig loyale Großkunden zu binden und bislang nicht klar erkennen lässt, wer von den erbitterten Konkurrenten wirklich substanzielle technische Vorteile haben könnte.
Auch andere Zahlen aus dem KI-Universum sind schwindelerregend: Googles Konzernmutter Alphabet will nach einem Bericht des Economist dieses Jahr seine Ausgaben um 50% auf 48 Milliarden Dollar steigern – den größten Teil davon in KI-Entwicklung. Alphabet, Microsoft, Amazon und Meta sollen dieses Jahr insgesamt rund 100 Milliarden Dollar in neue Datacenter stecken, in denen dann KI-Modelle auf Spezialchips leben.
Alles in allem werden die Investitionen in neue Computing-Infrastruktur für die KI-Entwicklung für den Zeitraum von 2024 bis 2027 auf 1,4 Billionen Dollar (ja, europäische Billionen, entsprechend US-Trillionen) geschätzt. Entsprechend hoch ist der Druck auf die beteiligten Firmen, solche Ausgaben möglichst zügig in vermarktbare Produkte umzusetzen, sonst droht eine Bestrafung am Aktienmarkt, in dessen Bewertungen die Zukunftsaussichten ja bekanntlich schon "eingepreist" sind. So wird OpenAI früher oder später die Hosen herunterlassen müssen, was denn nun GPT5 kann, oder was an den genüsslich befeuerten Gerüchten über eine angeblich schon im Geheimen werkelnde allumfassend intelligente KI (AGI) in ihren Labors dran ist.
Was davon fundierter Entwicklungsplan und was Blasen-Marketing ist, wird erst aus der Rückschau erkennbar werden.
Einstweilen übt sich Alphabet-Chef Sundar Pichai in fast Merkelscher Sachzwang-Logik:
Das Risiko zu wenig [in KI] zu investieren ist dramatisch größer als das Risiko zu viel zu investieren.
Sundar Pichai, CEO von Google und dessen Mutterkonzern Alphabet
Aber beschäftigen wir uns noch ein wenig mit konkret Bild-relevanten KI-News der letzten Zeit:
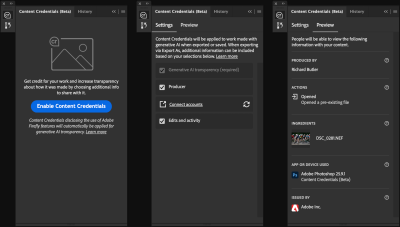
Adobe ermöglicht jetzt, in Camera Raw, Lightroom und Photoshop, die angekündigten "Content Credentials" in die Metadaten hinzufügen.
Die Kollegen von dpreview beschreiben die Handgriffe, die man dazu tun muss, und noch wirkt das Ganze recht hakelig und unfertig. Sinn der Sache soll ja sein, dass endgültige Betrachter eines so erstellten Bildes durch den Klick auf ein Verifizierungs-Link nachprüfen können, welche möglicherweise verfälschenden Bearbeitungsschritte ein Foto durchlaufen hat, bis es z.B. auf einer Website erscheint.
Dabei muss man sich allerdings bewusst machen, dass die nun vorgestellten Werkzeuge hier am Computer des Bildbearbeitenden willkürlich den Startpunkt für die Bearbeitungskette legen. Ob also das in Photoshop signierte Bild tatsächlich aus einer Kamera stammt und die behauptete Realität wiedergibt, beweist ein solches Credential mitnichten. Wir haben es also hier mit einem technologischen Zwischenschritt zu tun (auf dem Weg zu vielleicht in Zukunft direkt in der Kamera signierten Fotos), der vermutlich eher dazu einlädt, weitere Unsicherheit in die Authentizitätsdebatte zu bringen, wenn demnächst Bildfakes mit Credentials auftauchen, bei denen nur ExpertInnen erkennen können, dass diese nichts beweisen.
Weiteren Grund zur Beunruhigung bereitet mir dieses sehr technische Hacker-Paper, das zeigt, dass ausgerechnet die cryptographischen Zertifikate, die Adobe und Microsoft für die Erstellung von C2PA-konformen Bildsignaturen verwendet werden, relativ leicht zur scheinbaren Besiegelung von offenkundigen Bildfakes mißbraucht werden können. Wenn ich bedenke, welche Probleme ich im Jahr 2024 habe, simple verschlüsselte Mails mit etablierten Banken und Steuerkanzleien auszutauschen, ohne dass in regelmäßigen Abständen nicht irgendwelche Infrastruktur ähnliche Zertifikate unberechtigt abweist oder durch einen falschen Klick ungerechtfertigt akzeptiert, dann scheint es wirklich noch ein recht langer Weg zu sein, bis solche Methoden so selbstverständlich funktionieren, dass wir ihnen im täglichen Umgang vertrauen und sie intuitiv anwenden können.
Der oben verlinkte Artikel erklärt, wie Adobe Stock nun seinem dort eingebauten Bildgenerator Fesseln anlegt, um NutzerInnen daran zu hindern, mit seiner Hilfe Stilkopien bekannter KünstlerInnen zu erstellen.
Den Anstoß gab ja unlängst die Empörung der Nachlassverwalter von Ansel Adams, die erreichten, dass Adobe Bilder aus seiner Stock-Library entfernten, die sogar in der Bildbeschreibung damit warben, KI-Generate im Stil des Fotografen zu sein. Nichtsdestotrotz konnte man durch Eingabe entsprechender Prompts im generativen Teil derselben Plattform sich selbst ähnliche Bilder stricken. Das soll nun vorbei sein, indem Prompts mit Wünschen wie "im Stile von...." in Zusammenhang mit bestimmten BildautorInnen verboten sind, ebenso wie Referenzen auf bestimmte real existierende Persönlichkeiten wie auch bekannte markenrechtlich geschützte fiktionale Figuren.
Ein schönes Beispiel für die Schaffung neuer Berufe im Gegengewicht zum Jobverlust durch disruptive Innovationen. Freigesetzte BildredakteurInnen können jetzt auf ZensurlistenpflegerInnen oder ComicfigurencopyrightschützerInnen umschulen.
Meta kündigt unterdessen ein neues Tool zum lustvollen Realitätsverlust an. Das Kommando "Imagine Me" soll in naher Zukunft auf alles Plattformen des Konzerns verfügbar sein. Damit können sich NutzerInnen von Facebook oder Insta-Accounts in beliebige Outfits oder Umgebungen hineinimaginieren und das Bildergebnis natürlich gleich mit der Welt teilen.
Das Feature basiert auf einem neuen hier technisch beschriebenen Bildgenerator, der im Gegensatz zu anderen Modellen auf detailliertes Finetunig der Prompts verzichtet. Aus dem Forschungsaufsatz stammt auch die Bildersammlung unten, die basierend auf einem einzigen Referenzfoto der Forscher am unteren Rand der Abbildung unterschiedlichste Bildergebnisse und -stile auswirft.

Quelle: Meta
Bis demnächst
Jürgen