KI-Wochenpost 2024-36/38

er europäische AI-Act ist nun im zweiten Monat in Kraft, und keiner hat's gemerkt, oder? Kommt drauf an. Auch wenn sich für die Normalos unter den Anwendenden noch nicht so viel getan hat, hat der Startschuss des nach Eigenlob epochalen Regelwerks hinter den Kulissen hektische Aktivität ausgelöst.
Recht ungewohnt kurzfristig hat die EU Aufrufe zu diversen Beteiligungsverfahren für die zukünftige Ausgestaltung des regulatorischen Rahmens ausgerufen. Bis zum 25. August waren Organisatoren aufgerufen, ihr offizielles Interesse an der Teilnahme zu den Konsultationen zur Ausarbeitung des "General-Purpose AI Code of Practice" zu bekunden, also einer Art Verhaltenskodex für den Umgang mit allgemeinen KI-Systemen. Der Online-Fragebogen entpuppte sich als im Detail recht frickelig, doch es ist uns gelungen, diesen sprichwörtlich Minuten vor der Deadline als Deutscher Fotorat auszufüllen. So musste begründet werden, mit welcher Berechtigung man sich als relevanter Gesprächspartner sieht. Ganz wichtig aus Sicht der Regulierenden: Es dürfen nur Entitäten an den Beratungen teilnehmen, die ins europäische Transparenzregister eingetragen sind. Das haben wir kurz vor Schluss getan und bekamen die Bestätigung erst einen Tag danach. Mal sehen, ob uns das zum Verhängnis wird...
Als nächstes war ein EU-Fragebogen zur "Multi-stakeholder Consultation" auszufüllen mit dem Titel "FUTURE-PROOF AI ACT: TRUSTWORTHY GENERAL-PURPOSE AI". Den Zweck des Verfahrens erläutert das Europäische Amt für KI so:
Die Konsultation bietet allen Interessenträgern die Möglichkeit, zu den Themen des ersten Verhaltenskodex Stellung zu nehmen, in dem die Regeln für Anbieter von KI-Modellen für allgemeine Zwecke im Einzelnen dargelegt werden. Die Konsultation wird auch Informationen über die diesbezüglichen Arbeiten des Amtes für künstliche Intelligenz enthalten, insbesondere über das Muster für die Zusammenfassung der Inhalte, die für die Schulung der universellen KI-Modelle verwendet werden, und die begleitenden Leitlinien.
Alle interessierten Parteien werden zur Teilnahme aufgefordert. Das Amt für künstliche Intelligenz fordert ein breites Spektrum von Interessenträgern auf, Beiträge einzureichen, darunter Hochschulen, unabhängige Sachverständige, Vertreter der Industrie wie Anbieter allgemeiner KI-Modelle oder nachgeschaltete Anbieter, die das Modell in ihre KI-Systeme integrieren, Organisationen der Zivilgesellschaft, Rechteinhaber und Behörden.
Hier hat die Initiative Urheberrecht (IU) verdienstvolle Grundlagenarbeit geleistet, denn als pdf ist das Formular 34 Seiten lang. Hier gilt es, in sicherem Juristenenglisch die treffenden Wendungen zu finden, um unser Missfallen darüber zum Ausdruck zu bringen, dass beim Training aktueller KI-Modelle insbesondere bei Systemen zur Bildgenerierung bisher eher lax mit dem schöpferischen Eigentum der BildautorInnen umgegangen wurde. Wir haben auch die Gelegenheit genutzt, in einem individuellen Textanhang darauf hinzuweisen, dass die gegenwärtige Rechtsauffassung komplett praxisfern ist, ein "maschinenlesbarer" Vorbehalt gegen die Nutzung eigener Bilder für das KI-Training sei auf jeder Website durch die sogenannte "robots.txt"-Datei mit peniblem Hausverbot für jeden einzelnen namentlich bekannten Bot zu dokumentieren.
Auch hier sind wir sehr gespannt, auf welche Weise und in welchem Umfang wir im weiteren Verfahren Gehör finden. Jedenfalls schonmal ganz herzlichen Dank an alle, die an diesem Milestone mitgemeißelt haben! Eigentlich ist das ein Fulltime-Job für gutbezahlte Lobbyisten (die wir leider derzeit nicht haben).
Gerne kamen wir auch der Bitte des Bundesministeriums für Wirtschaft und Klimaschutz nach, ihnen unsere Stellungnahme zur Info zu schicken. Das Ministerium hatte im August ebenfalls zu einem ersten Stakeholder-Austausch geladen. Dort äußerten vor allem viele Teilnehmende viele Fragen und scheinen ähnlich gespannt zu sein wie wir, was das in der Praxis für Folgen haben wird.
Leider deutet bislang vieles darauf hin, dass sich der Europäische AI-Act in der Tat zu einem "Compliance Monster" entwickelt, wie auch in dieser Folge des Heise-Datenschutz-Podcasts die Spezialisten resümieren
Er würde damit in die Fußstapfen der DSGVO treten, deren Ziel zwar im Ansatz das Unterbinden von Missständen ist, sich zum größten Teil aber im peniblen Definieren von Randbedingungen und Voraussetzungen für "Rechtssicherheit" ergeht, was dazu führt, dass jeder von uns gefühlt 100 mal am Tag seine Cookie-Präferenzen bestätigen muss, aber als FotografIn in dem Bewusstsein lebt, dass man bei der Ausübung seines Berufs kaum eine Chance hat, alles wirklich 100% richtig zu machen. Oder habt Ihr z.B. das Merkblatt des Berliner Datenschutzbeauftragten in der Fototasche?
https://www.datenschutz-berlin.de/themen/medien/foto-und-videoaufnahmen/
Der AI-Act sieht ja im Kapitel Transparenzvorschriften zukünftig auch Kennzeichnungspflichten für den Output von KI-Systemen vor. Demnach soll in spätestens 24 Monaten, wenn auch dieser Teil inkrafttritt, klar sein, wie und in welchem Umfeld KI-generierte Bilder gekennzeichnet werden müssen. Allerdings geben schon die derzeitigen Formulierungen im Act Anlass zum Stirnrunzeln, denn so scheint die Notwendigkeit zur Kennzeichnung davon abzuhängen, ob das Bild vollständig generiert wurde, oder ob das Ausgangsmaterial ein Foto war, und ob die KI in "unterstützender Funktion" tätig war oder die vom Nutzer benutzten "Eingabedaten" "unwesentlich verändert" wurden. Es fällt sehr schwer, sich auszumalen, nach welchen Kriterien Juristen in der Zukunft hier Grenzen ziehen wollen, und wie das Rechtssystem mit seinen Instanzenwegen und Präzedenzurteilen hier jemals mit der aktuellen Entwicklung der Tools wird mithalten können.
Wir glauben, hier müssen die Praktiker aus eigenem Antrieb nach Lösungen suchen. Zu diesem Zweck lädt der Fotorat am 11. Oktober Interessierte aus Bildredaktionen, Agenturen und Verlagen zu einem Roundtable in Hamburg ein. Eine erste Diskussionsrunde per Zoom war sehr interessant und offenbarte großen Gesprächsbedarf. Denn schon heute gehen in den Redaktionen journalistisch arbeitender Medien Leserbriefe ein mit dem Tenor "Euren Fotos glaube ich sowieso nicht mehr", und auch die BildbeschafferInnen im Bereich Werbung und Corporate Publishing erleben die Bildung von Lagern zwischen jenen, die durchaus gerne die umständliche Fotografie durch Bildgeneration auf Knopfdruck ersetzen würden und anderen, die selbst beim simplen Abbilden einer Tomate Wert auf ein authentisches Foto legen.
Da wir es in Sachen Einspruch gegen Bildersaugen für KI-Training nicht bei kritischen Anmerkungen von der Seitenlinie belassen wollen, entstand in der Arbeitsgruppe die Idee, Fotografierenden praktische Werkzeuge an die Hand zu geben, mit denen sie ihre Rechtsposition stärken können. Erstes Resultat dieser Überlegungen ist der IPTC-Tagger:
In der Tat ist einer der Dreh- und Angelpunkte derzeitiger rechtlicher Scharmützel die Frage, ob denn die Urheber von Bildern, die nun gegen die Verwendung Ihrer Werke beim Training von Bildgeneratoren vorgehen wollen, beizeiten ihren Vorbehalt in geeigneter "maschinenlesbarer Form" zu erkennen gegeben haben.
Dabei scheinen Gerichte dazu zu neigen, entsprechende Klauseln in den Nutzungsbedingungen z.B. von Bildagenturen nicht für maschinell lesbar zu halten. Eifrig unterstützt wird diese Ansicht ausgerechnet von jenen Entwicklern, die ihre unter dem gleichen Dach entwickelten Sprachmodell als digitale Assistenten preisen, die imstande sind, komplizierte Sachverhalte aus großen Textmengen zu extrahieren und allgemeinverständlich zusammenzufassen. Bis der Streit um die korrekte Interpretation entschieden ist, dürften Jahre vergehen.
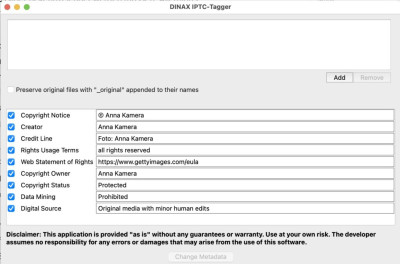
Da empfiehlt es sich, schon heute entsprechende Willensbekundungen in den Bildern selbst zu verankern. Das geht nämlich schon seit einiger Zeit in den sogenannten IPTC-Daten. Das sind Metadaten in jedem Bild, in denen Dinge wie der Typ der Kamera, Aufnahmezeitpunkt, Blende, Verschlusszeit und möglicherweise GPS-Daten stehen. Dort kann man auch Copyright-Vermerke einbetten und eben ein genormtes "Data Mining"-Statement, das die Nutzung zum KI-Training oder für Suchmaschinen erlaubt oder verbietet:

Ebenfalls relativ modern ist das Feld "Digital Source", das die Klassifizierung des Bildes in sehr feine Nuancen zwischen rein synthetisch erzeugten Werken und Originalfotografien zuläss.

Nur leider zeigen übliche Standardwerkzeuge wie Photoshop und Lightroom einige dieser Felder gar nicht an, oder machen das Ändern dieser Daten zu einer umfangreichen Klick-Orgie.
Dankenswerterweise hat AG-Mitglied Peter Hytrek, im wahren Leben Chef der DINAX GmbH, einige Stunden seiner Entwickler spendiert, um das Konzept des Taggers Wirklichkeit werden zu lassen.
Mit dem kleinen Programm können FotografInnen in ganzen Stapeln von Bildern einzelne oder alle dieser Rechte-relevanten Daten auf gewünschte Werte setzen, bevor sie beispielsweise Bilder ins Netz stellen oder an Kunden weitergeben.
Natürlich lässt sich derzeit nicht garantieren, ob das wirklich gegen das Einverleiben durch Bildgeneratoren schützt, denn dafür müssten die Bildsauger solche Einträge respektieren. Auch ist es derzeit üble Praxis vieler Plattformen, auf denen Bilder geteilt werden, die Metadaten nach dem Hochladen schlicht komplett zu löschen. Aber zumindest muss man sich dann nicht mehr von Gerichten und den Betreibern von Trainingsdatenbanken sagen lassen, man habe ja nicht ahnen können, dass jemand mit dieser Nutzung nicht einverstanden war.
Den Tagger gibt es hier zum kostenlosen Download:
Es bleibt leider in diesem Post schwerpunktmäßig trocken juristisch. Für Hartgesottene empfiehlt sich die Lektüre der gerade veröffentlichten Tandemstudie von Prof. Dr. Tim W. Dornis (Universität Hannover) und Prof. Dr. Sebastian Stober (Universität Magdeburg) im Auftrag der Initiative Urheberrecht. Der 218-seitige Wälzer kann hier kostenlos heruntergeladen werden:
Die beiden Spezialisten setzen sich im Detail mit dem Prozess des Datensammelns für das Training von KI-Modellen auseinander und hinterfragen die Ansicht der KI-Entwickler, hier würde das Urheberrecht nicht verletzt, denn es würden erstens keine Werke "vervielfältigt", und zweitens falle das Sammeln von Trainingsdaten unter die "Data Mining Schranke."
Mit diesem Passus wollten die Gesetzgeber seinerzeit rechtliche Hürden für Forschungsvorhaben beseitigen, doch Kritiker bestreiten, dass sich die Hersteller kommerzieller KI-Systeme auf dieses Forschungsprivileg berufen können.
Hier gibt es eine Zusammenfassung der Ergebnisse und hier die dazugehörige Pressemitteilung. Knackiges Zitat dazu:
Diese Studie hat Sprengkraft, weil sie belegt, dass wir es hier mit einem groß angelegten Diebstahl am geistigen Eigentum zu tun haben. Nun liegt der Ball bei der Politik, daraus die nötigen Konsequenzen zu ziehen und dem Raubzug zu Lasten von Journalist:innen und anderen Urheber:innen endlich ein Ende zu setzen
Hanna Möllers, Justiziarin des DJV
Zum Abschluss des juristischen Exkurses hier noch ein Hinweis auf eine aktuelle Stellungnahme des Deutschen Presserats:
Der Rat ermahnt Redaktionen zum ethischen Umgang mit KI-Bildern und erklärt: "Es darf nicht der Eindruck entstehen, dass künstlich generierte Bilder die Realität abbilden." Gefordert wird die Kennzeichnung als "Symbolbild".
Das ist insofern interessant, als darauf verzichtet wird, eine gesonderte spezielle Kennzeichnung für KI-Generate einzuführen. Die Symbolbild-Richtlinie gibt es schon länger und bezieht sich auf "insbesondere eine Fotografie, [die] beim flüchtigen Lesen als dokumentarische Abbildung aufgefasst werden [kann]".
Ich persönlich finde das sehr vernünftig, denn worin läge der Gewinn, beispielsweise eine vom Stock-Fotografen mit Models gestellte Krankenhausszene anders zu kennzeichnen als die KI-generierte Pseudo-Krankenschwester, wenn beide ähnlich aussehen, aber eben nicht das zeigen, was man zu sehen meint, nämlich ein Krankenhaus?
Zur Aufheiterung der Hinweis auf ein Interview mit dem ehemaligen Google-Chef Eric Schmidt. Er plauderte vor Studenten der Stanford-Uni aus dem Nähkästchen des Silicon Valley und fasste die "übliche Vorgehensweise" trocken so zusammen: Mann müsse sich nicht besonders um geistiges Eigentum Anderer beim harten Kampf um Marktanteile kümmern. Entweder, man werde schnell so erfolgreich und reich, dass man sich teure Anwälte leisten kann, die das Schlamassel hinterher wieder geradebiegen, oder man geht schnell unter, weil das Produkt niemanden interessiert, und damit krähe auch kein Hahn mehr nach eventuellen Fehltritten.

Überwiegend kritisch sehen Tester der neuesten Google-Smartphones der Serie "Pixel 9" die damit freigeschalteten KI-Funktionen des "Google Magic Editors".
Ohne das Phone aus der Hand zu legen, lassen sich im Editor mit simplen Prompts gerade aufgenommene Fotos zu alternativen Realitäten ummodeln. So konnten Ausprobierende harmlose Straßenszenen in Unfallorte verwandeln oder Erdbebenfolgen und Überflutungen simulieren.
Die KI-Kennzeichnung in den Screenshots stammt von den Online-Medien. Als BesitzerIn eines Pixel-Phones kann man die re-imaginierten Bilder problemlos auf Facebook und Instagram teilen, ohne dass dort irgendwelche verräterischen Labels auftauchen würden. Zumindest derzeit scheinen die KI-Änderungen im Magischen Editor keine Spuren in den Metadaten der manipulierten Bilder zu hinterlassen.
Damit erleben wir gerade einen krassen Gegensatz zur Situation vor ein paar Monaten, als die automatischen Kennzeichnung mit dem "Made with AI"-Sticker durch Meta oft auch unveränderte Fotos inkriminierte oder das simple Entfernen von Sensor-Flecken in Photoshop einen Warnhinweis auslösen konnte.

Journalisten in Venezuela nutzen derweil KI-Avatare, um über Realitäten aufzuklären. Die synthetischen Reporter La Chama und El Pana berichten über Wahlfälschung und Unterdrückung in dem südamerikanischen Land. "Es ist nicht mehr vernünftig, vor der Kamera zu stehen", zitiert der Guardian die Initiatoren.
Die Journalisteninitiative Connectas erklärt zum Projekt:
„Operación Retuit“ ist eine Strategie, die ursprünglich entwickelt wurde, um die Zensur und Unterdrückung von Journalisten in Venezuela zu umgehen. Sie nutzt künstliche Intelligenz nicht, weil das Tool gerade in aller Munde ist, sondern um Journalisten vor dem harten Durchgreifen zu schützen, das nach der Wahl folgte.Heutzutage werden Journalisten verhaftet, weil sie über Wahlereignisse berichten. Und es gibt eine Informationsblockade durch Kommunikationsunternehmen, um die freie Verbreitung von Informationen einzuschränken.Aus diesem Grund zielt Operacion Retuit darauf ab, relevante und verifizierte Informationen bereitzustellen, die von einem Dutzend venezolanischer und internationaler Medienunternehmen verbreitet werden, die bei den Initiativen „Venezuela Vota“ und „#LaHoraDeVenezuela“ zusammenarbeiten.
Bleiben wir zuversichtlich, dass dieser KI-Einsatz eine Nischenanwendung bleibt
Bis baldJürgen